DeepChem 化学性质预测工具是一个基于 DeepChem 库的机器学习管道,专为化学属性预测设计。该工具支持回归任务(如预测溶解度)和分类任务(如预测毒性),适用于化学信息学和药物发现领域。用户可以从 MoleculeNet 中选择标准数据集(例如 Delaney、Tox21、BBBP)进行模型训练,并对用户提供的分子数据进行预测。工具通过采用不同的特征化方法(如 ConvMolFeaturizer、WeaveFeaturizer 等)和模型类型(例如 GraphConvModel、MultitaskRegressor),以期在复杂分子数据上实现最优的预测性能。
为了进行预测,用户需要提供一个 CSV 文件,文件必须包含以下必要信息:
文件格式示例:
Compound_ID,SMILES,Other_Feature1,Other_Feature2
Molecule1,C1=CC=CC=C1,,
Molecule2,CC(=O)OC1=CC=CC=C1C(=O)O,,
...
该格式确保工具能正确读取 SMILES 数据进行特征化。证据表明,SMILES 字符串的有效性直接影响预测准确性,因此建议使用 RDKit 等工具对其进行验证。
DeepChem 训练默认参数:这部分参数为工具内置
用户可通过命令行参数自定义工具行为,具体参数包括:
| 参数名 | 可能值/范围 | 默认值 |
|---|---|---|
| 数据集 | delaney, tox21, bbbp 等 | bbbp |
| 训练迭代轮数 | 10-500 | 100 |
| 输入文件路径 | 任意有效路径 | 无 |
| SMILES 列名称 | 任意列名 | SMILES |
数据集选择说明:
MoleculeNet 提供了多个标准数据集,常用的如 Delaney(主要用于溶解度预测)、Tox21(用于毒性分类)。每个数据集都有其特定的应用背景和数据分布,建议根据预测任务的具体需求选择最合适的数据集。例如:
训练轮次说明:
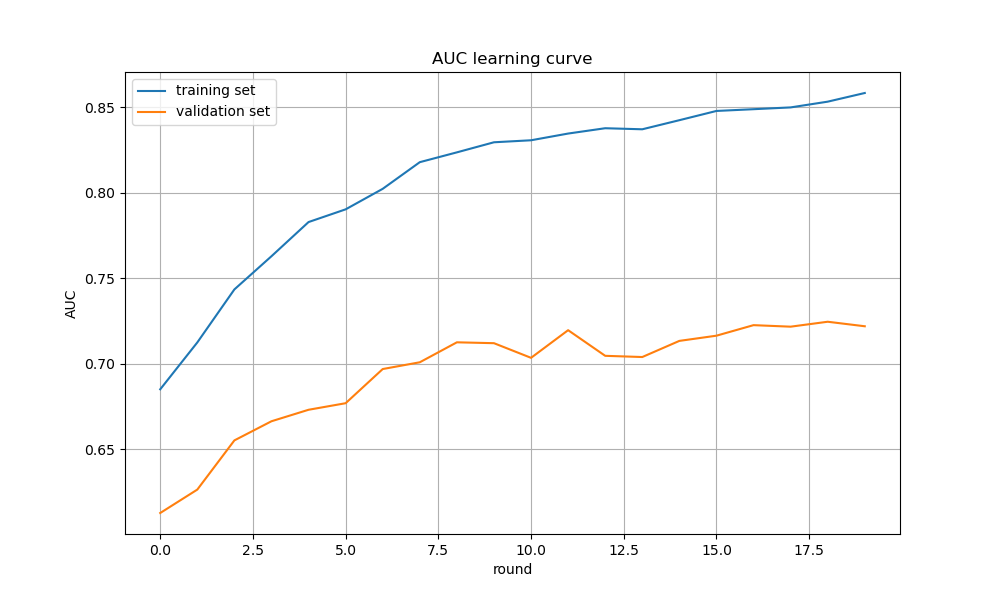
训练轮次(epochs)决定了模型在训练数据上迭代的次数。较多的轮次可以提高模型的拟合能力,但也可能导致过拟合。建议根据学习曲线监控模型性能,选择合适的轮次。
分子特征提取方法说明:
分子特征化是将分子结构信息转换为数值特征的过程,直接影响模型的表现。常用的特征化方法包括:
研究表明,不同的特征化方法在不同任务上会有显著的表现差异。本工具暂时只提供常用的 ConvMolFeaturizer 作为分子特征化方法。
结果文件夹——回归任务 ├──checkpoints [模型检查点文件夹] │ ├── checkpoint [模型检查点] │ ├── ckpt-[*]-data-00000-of-00001 [存储模型参数的二进制文件] │ └── ckpt-[*].index [模型参数索引文件] ├──predictions.csv [预测结果文件] ├──learning_curve_R2.png [R² 学习曲线图] ├──learning_curve_RMSE.png [RMSE 学习曲线图] └──scatter_plot.png [回归散点图]
结果文件夹——分类任务 ├──checkpoints [模型检查点文件夹] │ ├── checkpoint [模型检查点] │ ├── ckpt-[*]-data-00000-of-00001斐 [存储模型参数的二进制文件] │ └── ckpt-[*].index [模型参数索引文件] ├──predictions.csv [预测结果文件] ├──roc_curve_[task].png [ROC 曲线图] ├──learning_curve_AUC.png [AUC 学习曲线图] └──learning_curve_PRC-AUC.png [PRC-AUC 学习曲线图]
DeepChem 提供多种化学和生物数据集,每个数据集的任务不同:
该文件包含预测结果,列包括原始化合物 ID、SMILES 及每个任务的预测值:
| CompoundID | SMILES | OB | DL | pred_p_np |
|---|---|---|---|---|
| MOL001 | C1=CC=C(C=C1)O | 45.2 | 0.28 | -0.016190756 |
| MOL002 | CCOC(=O)C | 36.5 | 0.47 | 0.27431294 |
| MOL003 | CN(C)C(=S)NC | 49.1 | 0.33 | 0.056201834 |
| MOL004 | CC(C)C(=O)O | 33.7 | 0.56 | -0.42660084 |
| MOL005 | COC1=CC=CC=C1 | 42.8 | 0.39 | 0.27313095 |
| MOL006 | CSC1=CC=C(C=C1)Cl | 50.1 | 0.24 | 0.42337912 |
| MOL007 | CC1=CC=C(C=C1)Br | 47.6 | 0.3 | 0.41926923 |
| MOL008 | CC(=O)NC1=CC=C(C=C1)O | 39.4 | 0.45 | 0.051222 |
| MOL009 | CC1=C(C)C=CC=C1 | 41.3 | 0.4 | 0.48675323 |
保存训练过程中的模型状态,可用于恢复训练或进一步分析,但通常不需要用户直接解读。
根据任务类型,生成的图像文件有:

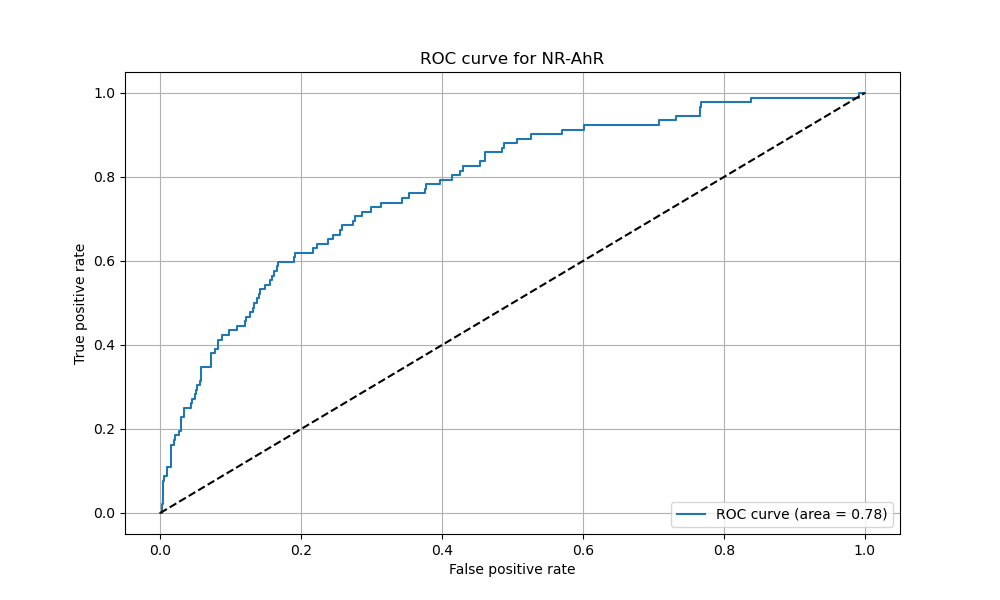
在解读时,请注意根据不同任务选择相应的图像进行对比分析,并参考图像中的趋势(例如:学习曲线中训练与验证曲线的接近程度、散点图中预测点与对角线的偏离、以及 ROC 曲线的形状和 AUC 值)来评估模型性能。
DeepChem 官方文档:https://deepchem.readthedocs.io/en/2.5.0/